After performing DIAMOND BLASTx and DAA “meganization” on 20220302, the next step was to import the DAA files into MEGAN6 for analyzing the resulting taxonomic assignments of the Crassostrea virginica (Eastern oyster) unmapped BSseq reads that Steven generated.
“Meganized” DAA files were imported into MEGAN6 (v.6.21.5), via the “Import from BLAST” dialog menu. All paired read DAA files were imported together (but not using the “paired reads” option, since I didn’t provide the corresponding FastQ files for this - no real reason; just didn’t think it necessary for this particulary analysis) using the megan-map-Jan2021.db for Taxonomy. This importation generated a single corresponding RMA6 (i.e one RMA6 file for each pair of DAA files). In retrospect, I should have just converted the DAA files to RMA6 during the DIAMOND BLASTx and DAA “meganization” on 20220302. It would’ve saved a lot of memory-related issues when trying to import many DAA files in a single MEGAN6 session…
After conversion to RMA6, a new “Comparison” was created, which allows visualization of taxonomic assignments across all samples, simultaneously.
RESULTS
Output folder:
-
20220309-cvir-unmapped_bsseq-megan/
-
MEGAN6 Comparison file (2.3MB):
-
It looked like the bulk of reads in all samples (i.e. > 75%) get assigned to the genus Crassostrea (see images at bottom of post).
Wordcloud of taxonomic assignments of reads for each sample (Genus level):

Phylogenetic tree of taxonomic assignments of reads for each sample (Genus level):
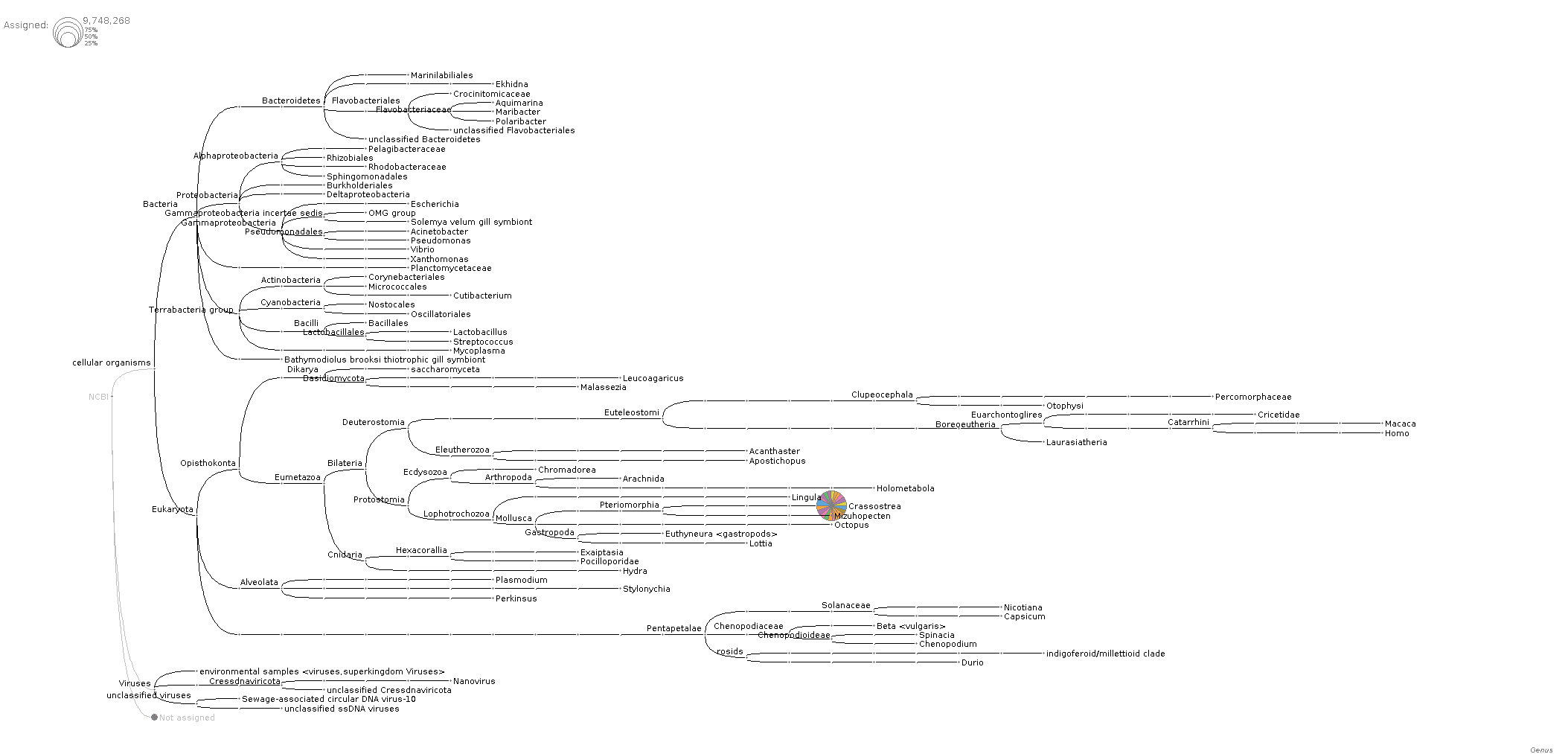
And, here’s the tree at the species level to help confirm that there’s not a bunch of C.gigas contamination and that it’s primarily Crassostrea virginica (Eastern oyster):
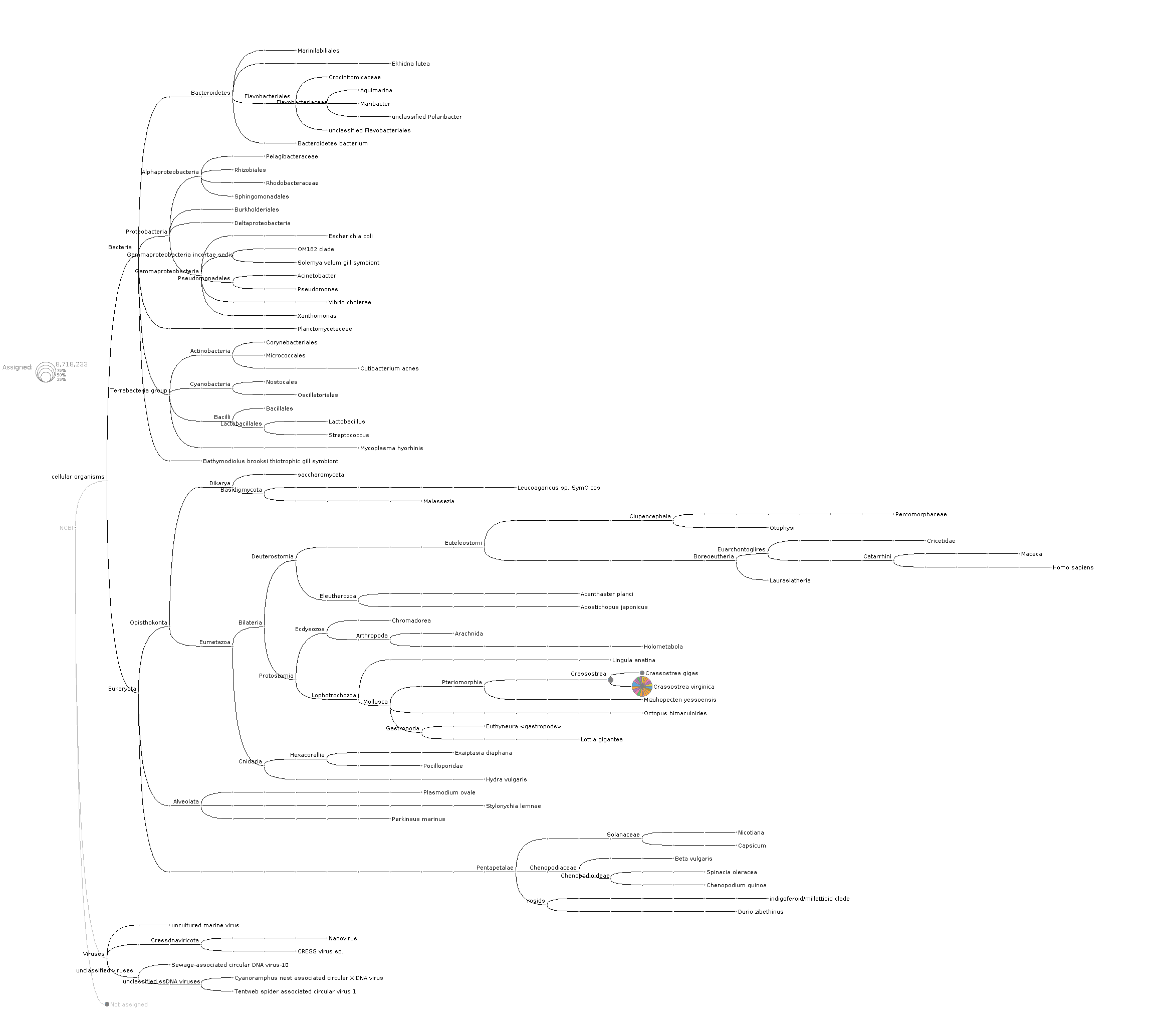
So, not sure why they’re not getting mapped originally.
I’m assuming these came from Bismark? If yes, the manual provides a bit of insight into capturing unmapped reads. Additionally, a comparison of unmapped reads and ambiguous reads might allow a better grasp of what’s happening:
--unWrite all reads that could not be aligned to the file _unmapped_reads.fq.gz in the output directory. Written reads will appear as they did in the input, without any translation of quality values that may have taken place within Bowtie or Bismark. Paired-end reads will be written to two parallel files with _1 and _2 inserted in their filenames, i.e.
unmapped_reads_1.fq.gzandunmapped_reads_2.fq.gz. Reads with more than one valid alignment with the same number of lowest mismatches (ambiguous mapping) are also written to unmapped_reads.fq.gz unless--ambiguousis also specified.
--ambiguousWrite all reads which produce more than one valid alignment with the same number of lowest mismatches or other reads that fail to align uniquely to _ambiguous_reads.fq. Written reads will appear as they did in the input, without any of the translation of quality values that may have taken place within Bowtie or Bismark. Paired-end reads will be written to two parallel files with _1 and _2 inserted in their filenames, i.e.
_ambiguous_reads_1.fqand_ambiguous_reads_2.fq. These reads are not written to the file specified with--un.