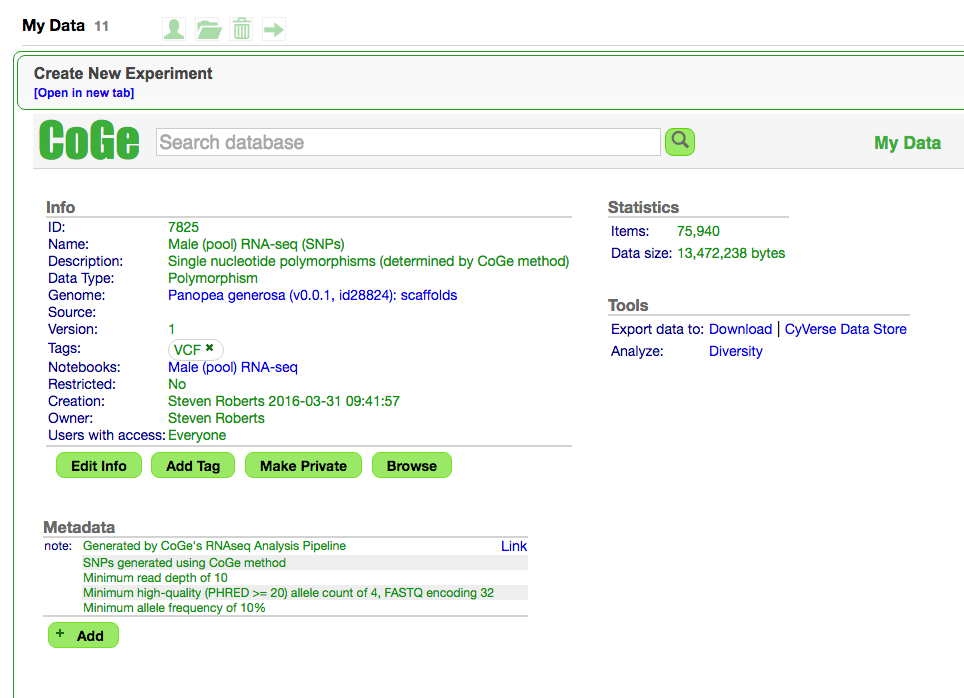
Work Accomplished
The overall goal of this project is to develop a fundamental understanding of processes controlling marine mollusc reproductive maturation. In order accomplish this goal the specific research objectives of this proposal were to 1) characterize tissue specific transcriptomic resources for the geoduck and 2) identify proteins that play a role in geoduck reproductive maturation.
The first step in this project was collecting clams at different reproductive stages as determined through histological analysis. Gonadal tissue from 70 geoducks was sampled in batches of about eight per week over the span of two months from November 2014 to early January 2015. Hundreds of images were analyzed and reproductive status was determined for each individual.
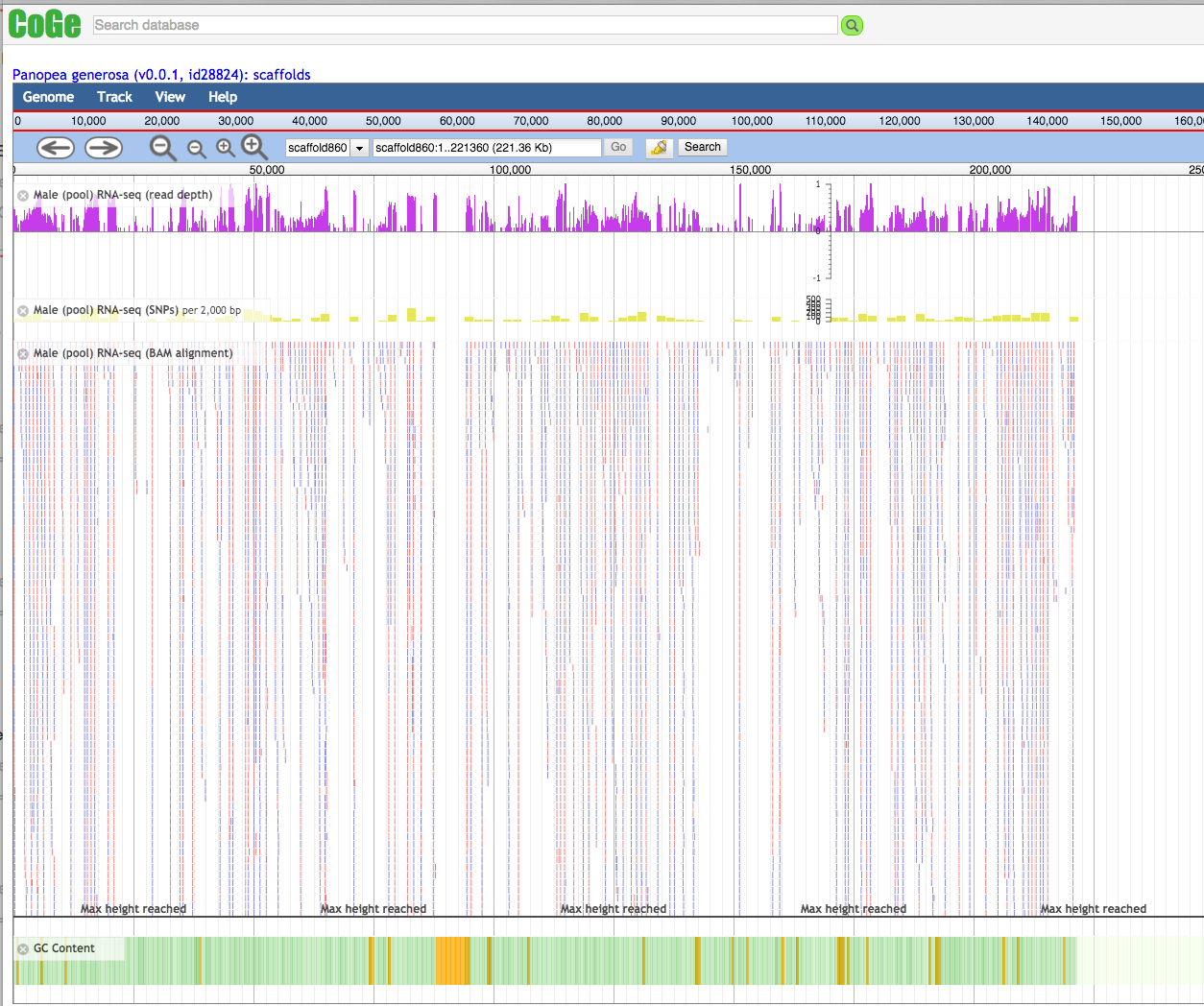
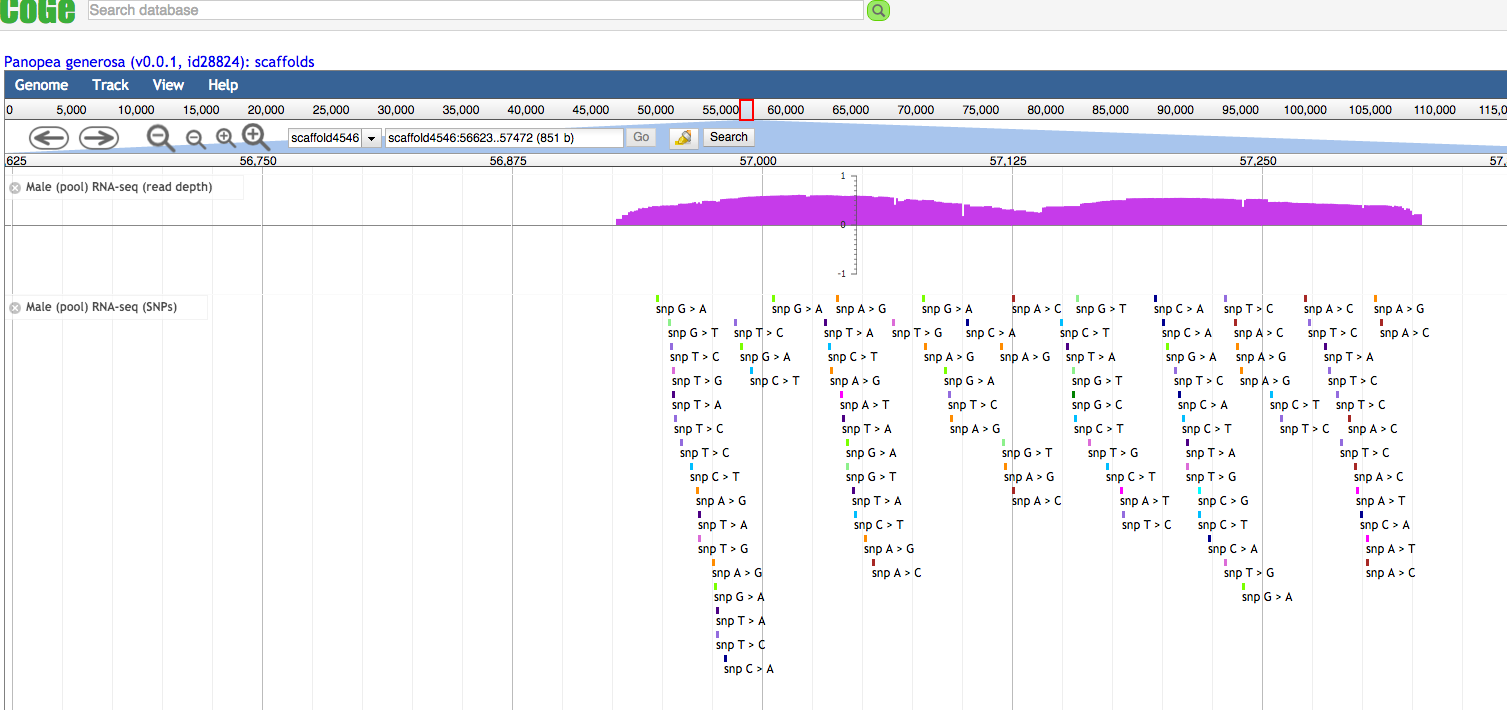
Based on histological determination of reproductive maturational stage, seven female and six male paraffin-embedded gonad samples were selected for construction of RNA-seq libraries. A total of 443,468,476 reads were obtained and the de novo assembly resulted in a total of 153,982 transcript contigs with a mean contig length of 660 bp and an N50 value of 1015 bp. In comparing our contigs with oyster sequences whose expression changed during gonad development in 161 matched including geoduck sequences corresponding to genes expressed in gonads in early gonad developmental stages (7), with increasing expression during spermatogenesis (44), with increasing expression during oogenesis (31) and genes with varying expression level during gonadogenesis in both sexes (79) .
Proteomic profiles were determined for the primary reproductive maturation stages in both male and female clams using data dependent acquisition (DDA) of gonad proteins. This approach yielded 3,627 detected proteins across both sexes and three maturation stages. This is a significant escalation in the understanding of proteomic responses in maturation stages of marine mollusks. Based on the DDA data, 27 proteins from early- and late-stage male and female clams were chosen for selected reaction monitoring (SRM). The SRM assay yielded a suite of indicator peptides that can be used as an efficient assay to non-lethally determine geoduck gonad maturation status.
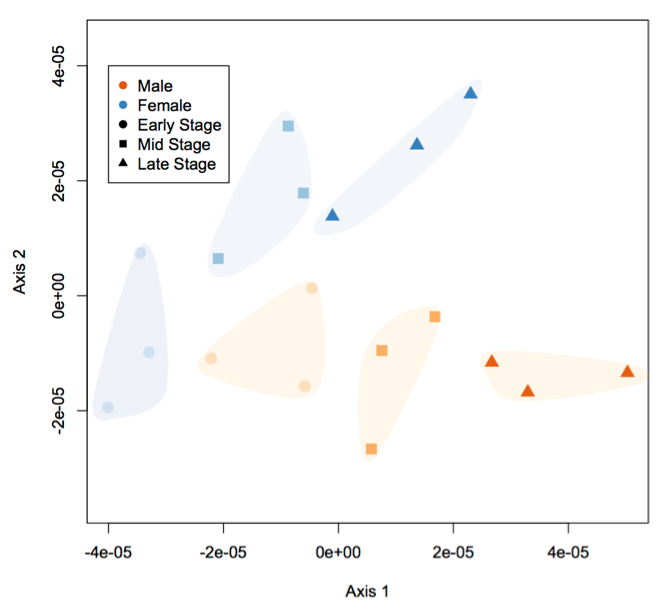
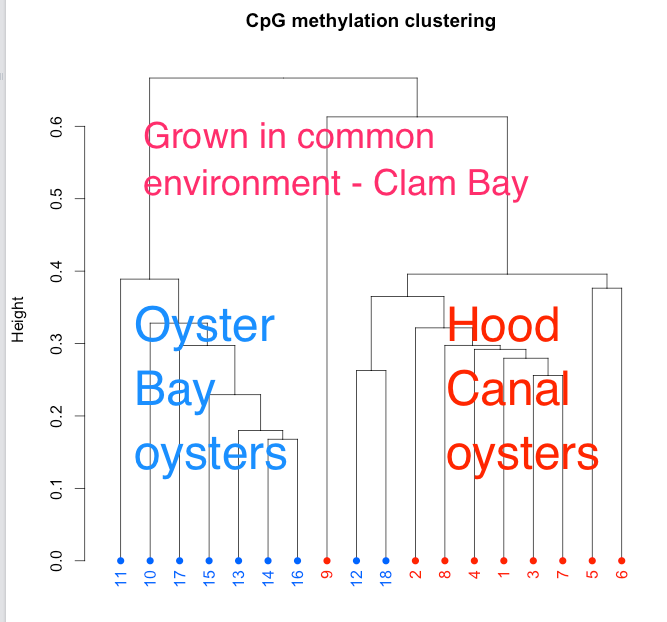
Non-metric multidimensional scaling plot (NMDS) of geoduck gonad whole proteomic profiles generated by data dependent acquisition. Gonad proteomes differ among clams by both sex (male = orange, female = blue) and stage (early-stage = circles, mid-stage = squares, late-stage = triangles; p<0.05).
Impact of Award
Beyond contributing to the fundamental knowledge of marine mollusk reproduction, this award produced numerous publications and provided basis for further funding and proposal submissions. In addition the transcriptomic data was the basis for the course: Bioinformatics for Transcriptomic and Epigenomic Analyses – Centro de Investigación Científica y de Educación Superior de Ensenada, B.C. (CICESE) 19-24 October 2015
Further Funding
Currently two projects have been funded that were based on this project and others have been submitted. Funded projects include: Proteomic response of shellfish to environmental stress; Department of Natural Resources $107,805 and Elucidating the physiological and epigenetic response of tetraploid and triploid Pacific Oysters to environmental stressors; NOAA $178,898. Submitted proposals include one to NOAA on the development of new clam species for aquaculture.
Publications
Crandall, Grace; Roberts, Steven (2016): Reproductive Maturation in Geoduck clams (Panopea generosa). figshare.
https://dx.doi.org/10.6084/m9.figshare.3205975.v1
Retrieved: 14 41, Dec 23, 2016 (GMT)
This fileset includes a research paper describing reproductive maturation in geoduck clams with 200 images of gonadal histological sections and associated datasheets. Downloads = 1761.
Emma B. Timmins-Schiffman, Grace A. Crandall, Brent Vadopalas, Michael E. Riffle, Brook L. Nunn, Steven B. Roberts (2016) Integrating proteomics and selected reaction monitoring to develop a non-invasive assay for geoduck reproductive maturation
bioRxiv 094615; doi: https://doi.org/10.1101/094615
[Data] Transcriptomic profiles of adult female & male gonads in Panopea generosa (Pacific geoduck).
https://www.ncbi.nlm.nih.gov/bioproject/PRJNA316216
Panopea gonad transcriptome
Open Science Framework Project
https://osf.io/3xf6m/
[Data] Geoduck (Panopea generosa) gonad DDA LC-MS/MS
https://www.ebi.ac.uk/pride/archive/projects/PXD003127
[Code] Source Code for GO Analysis in Geoduck Gonad Background
https://github.com/yeastrc/compgo-geoduck-public
[Data] Geoduck (Panopea generosa) gonad DIA LC-MS/MS
https://www.ebi.ac.uk/pride/archive/projects/PXD004921
[Data] Selected reaction monitoring of geoduck gonad peptides to develop biomarkers of reproductive maturation status
http://www.peptideatlas.org/PASS/PASS00943
[Data] Selected reaction monitoring of geoduck hemolymph peptides to develop biomarkers of reproductive maturation status
http://www.peptideatlas.org/PASS/PASS00942










Recent Comments