The prior run used a kmer size of 61, and the resulting assembly was rather poor (small N50).
For this run, I arbitrarily increased the kmer size to 101, in hopes that this will improve the assembly.
The job was run on our Mox node.
Here’s the batch script to initiate the job:
20180322_SparseAssembler_novaseq_geoduck_slurm.sh
#SBATCH --job-name=20180322_sparse_assembler_geo_novaseq
## Allocation Definition
#SBATCH --account=srlab
#SBATCH --partition=srlab
## Resources
## Nodes (We only get 1, so this is fixed)
#SBATCH --nodes=1
## Walltime (days-hours:minutes:seconds format)
#SBATCH --time=30-00:00:00
## Memory per node
#SBATCH --mem=500G
##turn on e-mail notification
#SBATCH --mail-type=ALL
#SBATCH --mail-user=samwhite@uw.edu
## Specify the working directory for this job
#SBATCH --workdir=/gscratch/scrubbed/samwhite/20180322_SparseAssembler_novaseq_geoduck
/gscratch/srlab/programs/SparseAssembler/SparseAssembler \
LD 0 \
NodeCovTh 1 \
EdgeCovTh 0 \
k 101 \
g 15 \
PathCovTh 100 \
GS 2200000000 \
i1 /gscratch/scrubbed/samwhite/20180129_trimmed_again/AD002_S9_L001_R1_001_val_1_val_1.fastq \
i2 /gscratch/scrubbed/samwhite/20180129_trimmed_again/AD002_S9_L001_R2_001_val_2_val_2.fastq \
i1 /gscratch/scrubbed/samwhite/20180129_trimmed_again/AD002_S9_L002_R1_001_val_1_val_1.fastq \
i2 /gscratch/scrubbed/samwhite/20180129_trimmed_again/AD002_S9_L002_R2_001_val_2_val_2.fastq \
i1 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR005_S4_L001_R1_001_val_1_val_1.fastq \
i2 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR005_S4_L001_R2_001_val_2_val_2.fastq \
i1 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR005_S4_L002_R1_001_val_1_val_1.fastq \
i2 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR005_S4_L002_R2_001_val_2_val_2.fastq \
i1 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR006_S3_L001_R1_001_val_1_val_1.fastq \
i2 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR006_S3_L001_R2_001_val_2_val_2.fastq \
i1 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR006_S3_L002_R1_001_val_1_val_1.fastq \
i2 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR006_S3_L002_R2_001_val_2_val_2.fastq \
i1 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR012_S1_L001_R1_001_val_1_val_1.fastq \
i2 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR012_S1_L001_R2_001_val_2_val_2.fastq \
i1 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR012_S1_L002_R1_001_val_1_val_1.fastq \
i2 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR012_S1_L002_R2_001_val_2_val_2.fastq \
i1 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR013_AD013_S2_L001_R1_001_val_1_val_1.fastq \
i2 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR013_AD013_S2_L001_R2_001_val_2_val_2.fastq \
i1 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR013_AD013_S2_L002_R1_001_val_1_val_1.fastq \
i2 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR013_AD013_S2_L002_R2_001_val_2_val_2.fastq \
i1 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR014_AD014_S5_L001_R1_001_val_1_val_1.fastq \
i2 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR014_AD014_S5_L001_R2_001_val_2_val_2.fastq \
i1 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR014_AD014_S5_L002_R1_001_val_1_val_1.fastq \
i2 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR014_AD014_S5_L002_R2_001_val_2_val_2.fastq \
i1 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR015_AD015_S6_L001_R1_001_val_1_val_1.fastq \
i2 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR015_AD015_S6_L001_R2_001_val_2_val_2.fastq \
i1 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR015_AD015_S6_L002_R1_001_val_1_val_1.fastq \
i2 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR015_AD015_S6_L002_R2_001_val_2_val_2.fastq \
i1 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR019_S7_L001_R1_001_val_1_val_1.fastq \
i2 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR019_S7_L001_R2_001_val_2_val_2.fastq \
i1 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR019_S7_L002_R1_001_val_1_val_1.fastq \
i2 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR019_S7_L002_R2_001_val_2_val_2.fastq \
i1 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR021_S8_L001_R1_001_val_1_val_1.fastq \
i2 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR021_S8_L001_R2_001_val_2_val_2.fastq \
i1 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR021_S8_L002_R1_001_val_1_val_1.fastq \
i2 /gscratch/scrubbed/samwhite/20180129_trimmed_again/NR021_S8_L002_R2_001_val_2_val_2.fastq
Results
Output folder: 20180322_SparseAssembler_novaseq_geoduck/
This completed much more quickly than the previous run (kmer = 61). The previous assembly took ~10 days, while this assembly completed in ~4 days!
The primary output file of interest is this FASTA file:
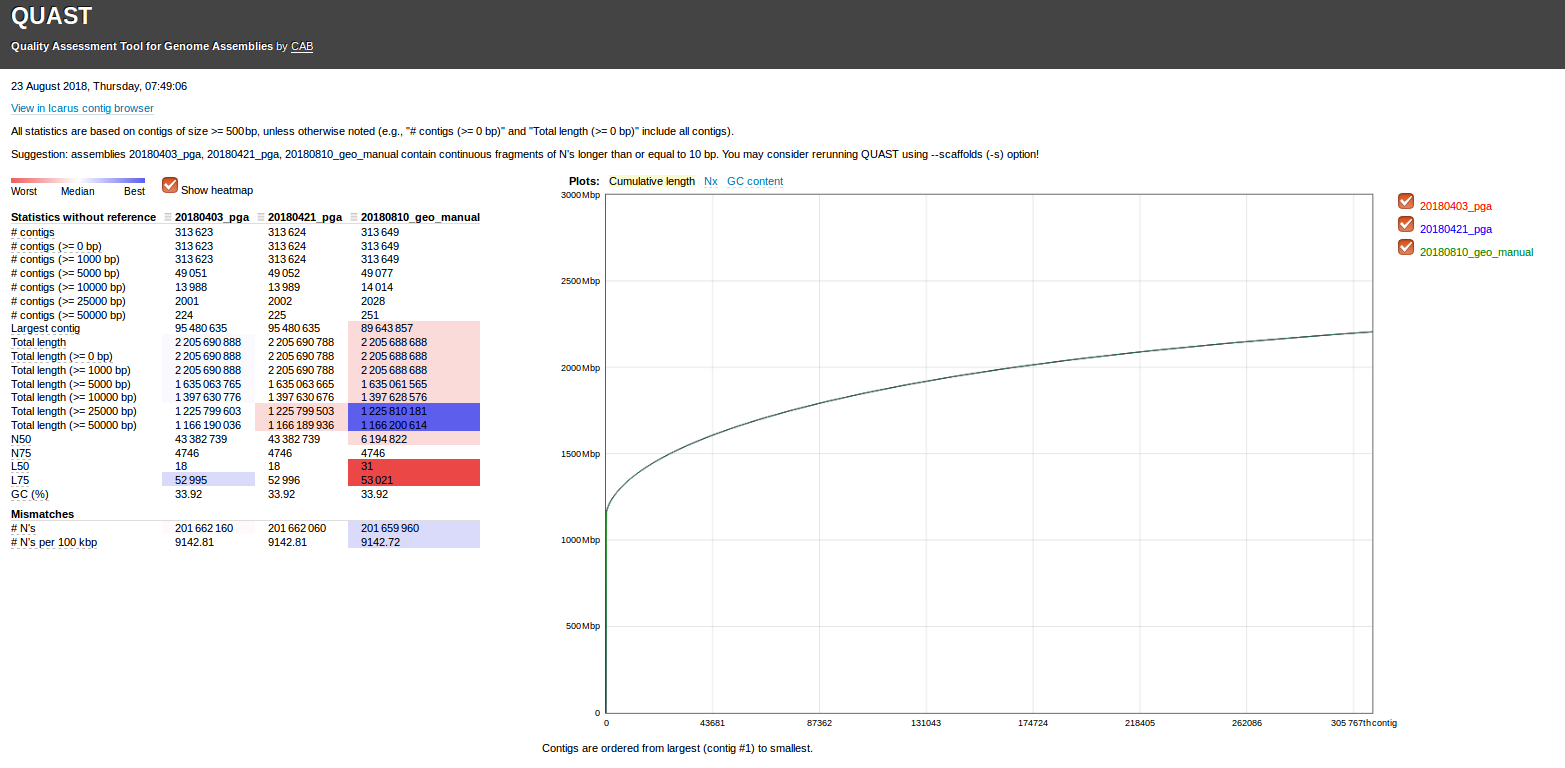
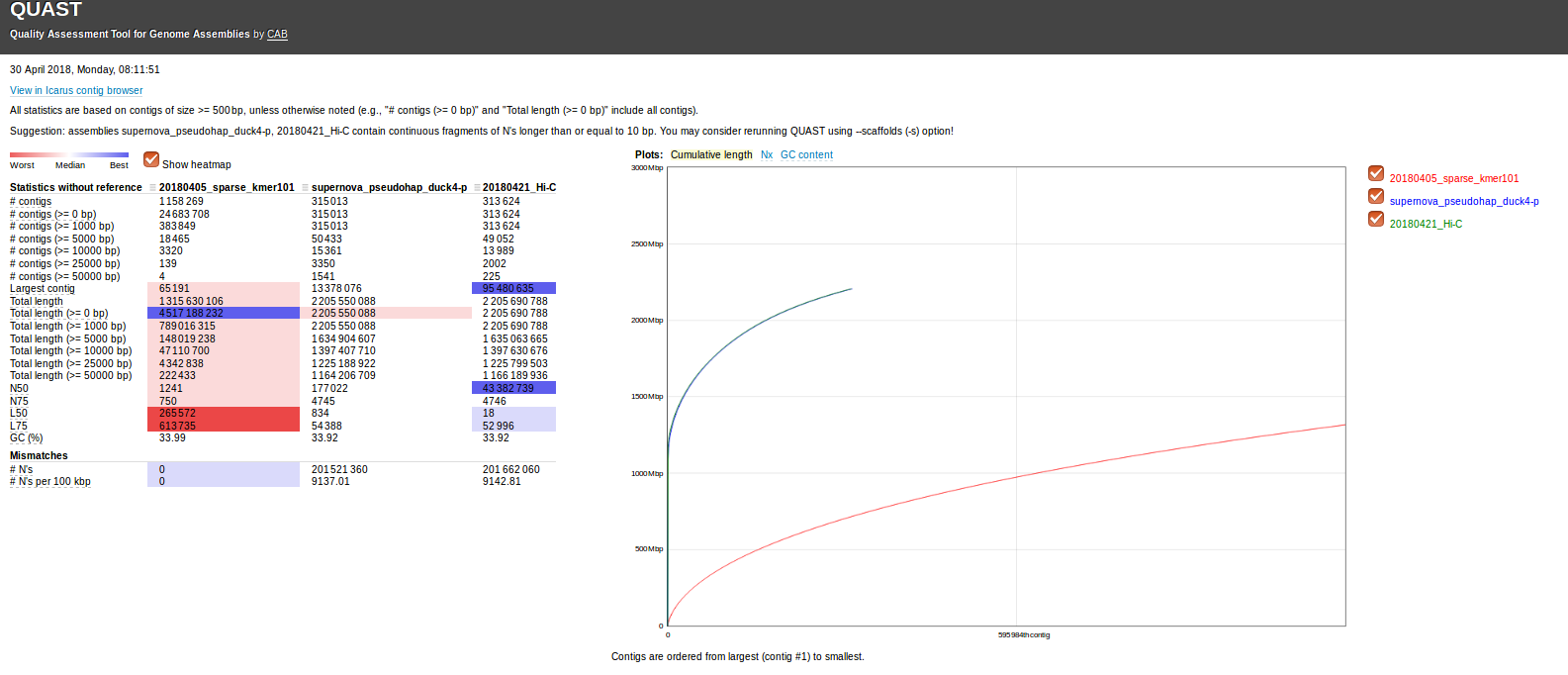
In order to get a rough idea of how this assembly looks, I ran it through Quast Version: 4.5, 15ca3b9:
python software/quast-4.5/quast.py \
-t 16
/mnt/owl/Athaliana/20180322_SparseAssembler_novaseq_geoduck/Contigs.txt
Quast output folder: results_2018_03_27_08_25_52/
Here’re the stats on the assembly:
Quast output (text): results_2018_03_27_08_25_52/report.txt
Quast output (HTML):results_2018_03_27_08_25_52/report.html
This is definitely a better assembly than the kmer = 61 assembly.
N50 = 1149
Also, there’s a single, large contig of 56,361bp, and 54 contigs > 25,000bp. This is good.
Admittedly, I’m a little surprised (and, disappointed) the N50 is as small as it is. However, we have a pretty decent assembly on our hands!
Since SparseAssembler seems to actually run (and, relatively quickly), I’m very tempted to just throw ALL of our geoduck data at it and see how it turns out…